Load All Columns as Alphanumeric overridden when loading Excel Workbook with multiple sheets
Answers
-
I've examined the code and it's not checking the date of the file anywhere, for manual refreshes at least. It just goes ahead and reads the file from the S3 bucket.
When you load it can you see it loading in the progress? It might be possible to observe this with a bigger file.
On the face of it the process is not failing which means it's able to connect to S3 and retrieve the file, only that file does not contain what we expect. Would you mind checking the log file to see if there are any errors in there - it's possible that one had occurred that we're not displaying in the UI.
Thanks,
Ian
0 -
I tried again this morning. The first time I tried, I simply refreshed the dataset in Aperture - it didn't work. When I used FileZilla to move the data across to my disk and then to move it back again so that the date in FileZilla was updated but nothing else was, then it updated as expected.
I tried making a larger file -(1,770 rows) and refreshed that but it didn't work. When I click on the "Apply" button in that intermediate screen, the little arrow goes around for about a second - I don't see any loading stats when the dataset screen reappears. Then I really pushed the boat out and increased the file to 19,500 rows and tried refreshing that as before - and it worked! I had a percentage loaded and then the full dataset. The only thing that was different was that I had refreshed another large dataset in the meantime to see the percentage figure.
So now I am confused of Oxford!
0 -
Just looking at the log (DataStudio.log), I see a succession of versions being deleted, as one would expect for a single-batch dataset. And as I am still seeing the dataset, then a new version must be being loaded - it is just that it is not picking up the new data from the SFTP server. I don't know what the S3 bucket, above.
It feels like refreshing the other dataset changed something in the sequence and caused the fresh data to be picked up - and maybe this is also reset on a daily basis, rather like the logs?
Best wishes,
Charles
0 -
Thanks Charles. So it's not the source's timestamp that's the problem then, but might be something to do with the dataset load. There is no code in Data Studio that limits refreshes based on any time elapsed or sequence - it should simply reload the data into the dataset as instructed. It's a bit baffling that it's not.
I wonder, if you try creating a new dataset from one of these non-refreshing sources, do they load the new data?
Regards,
Ian
0 -
If I try loading a new dataset from the SFTP server then it doesn't work, if I copy the file to a directory on the server (I used the default export directory) and uploaded a new dataset, then it did!

So the problem is somehow associated with picking up the new file from the SFTP server. I simply transferred the file from the SFTP server to my local drive and then copied and pasted that file into the directory on the RDP.
0 -
Interesting, thanks.
You implied earlier that your S3 datasets are doing the same thing, can you confirm?
0 -
Sorry, not quite sure what you mean by S3 datasets?
0 -
No problem, just one of your screenshots earlier mentioned AmazonS3 - is that an S3 datasource (i.e. via a connection to an Amazon AWS S3 filestore), or is it just a name given to one of your SFTP connections?
0 -
I don't recognise that one at all - we are only accessing files through the one SFTP server, though we have set it up a couple of times to have different root directories - one for the HR source data, one for exporting the HR data and the third for the customer source data.
0 -
Ok thanks, so it's SFTP only. I've been looking at the code and it's pretty straightforward really; it simply opens the SFTP connection and opens a channel to the file and streams the data into Data Studio. Loading it into a new Dataset (largely) eliminates any potential for already loaded data to be used instead of the new data from SFTP, but this still exhibits the problem. We have not encountered this issue anywhere else either, and we have quite a number of customers who use SFTP heavily.
I am wondering whether there is some caching or upload lag happening directly on the SFTP side (i.e. file is uploaded to a temp file and then moved to the correct location once the connection is closed). We might be able to verify this by tweaking your download/change/upload/Data Studio load process. Could you try this:
Download an existing file from SFTP to your PC, change the number of rows and upload it. Keep this sftp session open.
Open another sftp client and redownload the file - see if it contains the updated rows.
Load into Data Studio - the rows should be the same as above.
0 -
Hi Ian,
Thanks, I did this and the row counts looked good. I tried a second time and again they looked good. Then I was sneaky. Without changing the row count, I overwrote some rows, so that the contents of some rows were different. Looking at the output, it was not quite as I had expected. I exported the dataset and ran a compare on it - some 6 lines had been loaded in a different place:
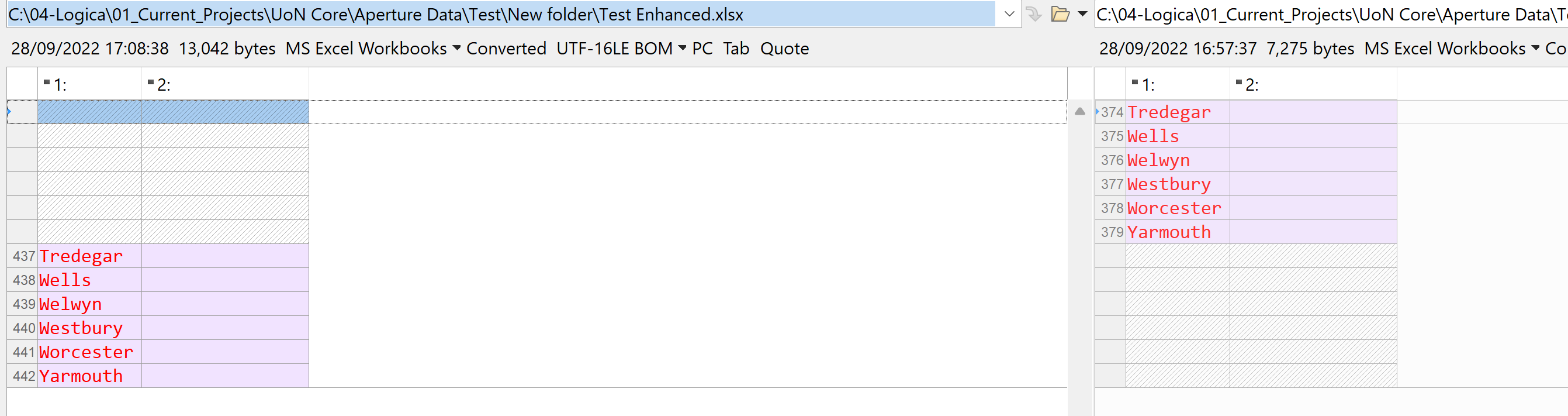
Strange!
0 -
Hi Charles, we can pick this up in our meeting tomorrow. It's very strange behaviour and I think I'll have to add some logging to the code to see what we're reading from SFTP. If we can establish that Data Studio is definitely reading the new data we can look into why it's not loading it.
Speak soon. Regards,
Ian
0

