Load All Columns as Alphanumeric overridden when loading Excel Workbook with multiple sheets

When loading multiple worksheets from a single Excel workbook, the columns are auto-converted rather than being loaded as alphanumeric as specified in the options. Splitting the sheets into separate workbooks allows the data to be loaded as required.
Is this a feature or a problem?
Answers
-
Hi Charles, I've not come across this previously, but we can look into it
Thanks
0 -
Hi Charles,
I've taken a look at this but cannot replicate what you've reported in the latest v2.8.7 of Aperture Data Studio.
If you could share the workbook that reproduces the problem I'd be happy to take a look.
Regards,
Ian
0 -
This is the picture of the loaded data set:

while this is the Define Settings screen:

and the file is attached - obviously, given the data, it is a test one. I am running 2.8.0.33.
Many thanks,
Charles
1 -
Hi Charles,
Thanks so much for providing screen shots and a test file.
I loaded it into 2.8.0 twice, once as auto-detect and once as alphanumeric. For the latter I see the same preview data as you, but upon load it appears correct - as-per the preview rather than the loaded data that you've copied in.
I've collated both versions (auto & alpha) below and both look as they should:

So there appears to be something rather more subtle happening.
I wonder, did you create new datasets when loading as alphanumeric, or did you upload new data into an existing dataset?
Regards,
Ian
0 -
Thanks, Ian, This was a completely new dataset, only ever loaded the once. The only possibly unusual thing about it is that I am loading it from an SFTP server that is defined as an external system I don't know whether it is relevant but I am sometimes having difficulties in refreshing the datasets from this - if I upload a new version of a different file to the server and then click on Refresh Data, sometimes it works and sometimes it doesn't. Hence the Test 1 to ensure a clean dataset.
Best wishes,
Charles
0 -
Hi Charles,
Thanks, that was the problem. I've reproduced the issue and will raise a bug to get it fixed. So we can prioritise it correctly, could you let me know how much of an inconvenience this is for you?
Thanks,
Ian
0 -
Many thanks Ian. The fact that updating the data isn't working is quite a problem as I upload files for use in Matching functions and these do get modified quite frequently while I am developing the logic. It is a real pain, and prone to error, to have to go through all the matching functions and update the table I am using because I have had to make a new one to grab the changes.
Best wishes,
Charles
0 -
Ok sounds like it's quite a nuisance so I'll make sure it gets looked into soon.
Many thanks for your time in helping me reproduce this.
Regards,
Ian
1 -
I am beginning to see the light! Probably because of the ability to refresh a dataset as part of a run, Aperture doesn't believe me when I say that I want to refresh a dataset. Rather, it looks at the date stamp to see if the source data has been refreshed - and only checks the date, not the date and time? Would explain why it works once a day!
Best wishes, Charles
0 -
Hi Charles,
I'll take a look into this and get back to you.
Regards,
Ian
0 -
Hello again @Charles Thomas.
I'm just checking in - I have talked with the team and they say that Data Studio should be checking the date and time of the file when refreshing. I have yet to verify this myself but will get to it soon.
Are you still consistently seeing this behaviour?
Regards,
Ian
0 -
Sadly yes, the first time I refresh the dataset in the day it updates, then I have to find patience and wait until the next day. Good practice in analysing the results carefully to get as many corrections as possible in at a time!
1 -
I've tested this and it seems to be working okay for me. You need to ensure that 3 flags are checked though; one on the source dataset definition 'Allow auto-refresh', one in the source step (named the same) and in the Run Workflow dialog 'Refresh Sources'. Scheduled jobs also require this to be set in the scheduled definition, although I did not test this scenario today.
I initially missed the last of these and my dataset did not refresh, however with all of them checked the dataset is reloaded from the SFTP source upon each workflow execution, even when there are just a few seconds between the file being updated.
Would you mind double checking these?
Thanks,
Ian
1 -
Sounds from the description like this is a manual refresh not automatic/workflow driven
 0
0 -
Yes, it is a manual refresh - but only of a specific dataset. I select the dataset(s) in question, click on the Actions menu and select Refresh data.
There is one more possible peculiarity - I am using the datasets in question as sources for Matches so that they haven't actually been loaded into the workflow as a source
As before, the first time I refresh the datasets on a day it works, after that it doesn't. I am using FileZilla to pull the files onto the SFTP server and am then should refresh the dataset from there.
0 -
The manual refresh (again) worked fine for me.
Do you see the confirmation dialog (i.e. the below) appear every time - for successful refreshes and failures?
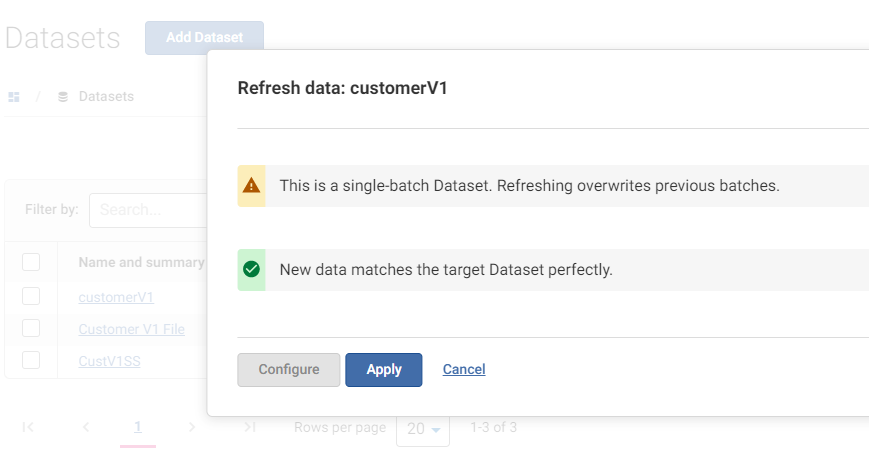 0
0 -
Yes, everything looks absolutely normal, excepting that the new data isn't loaded after the first refresh of the day!
0 -
Hi @Charles Thomas I had incorrectly assumed that you were reading this file from an SFTP source (as per the earlier issue), but I've just noticed it is coming from S3. This likely uses a different method of working out when the source needs updating. I'll look into this.
Regards,
Ian
0 -
@Charles Thomas this is still working for me using an S3 source.
Could you try something? It's how I test this locally:
- Load a small dataset
- Create a workflow to export this dataset to a new file on your S3 account and run it.
- Load this new file into Data Studio
- Edit the workflow to union the source with itself and export the output of that (doubling the rows), and run it.
- Refresh the S3 dataset, ensure the rowcount doubles.
- Redo again from step 4.
Thanks,
Ian
0 -
Done all of the above - the dataset remains set stubbornly on 21 lines:

But the file that I refreshed (the top one) has 42 lines (allowing for the header):



I bet that it will have 42 rows when I refresh it tomorrow morning.
Many thanks,
Charles
0

