Profiling many datasets of different schemas

Sueann See
Experian Super Contributor
To profile thousands of datasets easily, you can create a reusable workflow with a replaceable source. However, if each of the datasets have a different schema, you will have to determine what is the most number of columns a dataset can have and use a generic schema with generic column names in your workflow.
- Assuming your widest dataset has 3 columns, create a GenericSchema dataset that would represent this schema with generic column headings:

- Create a workflow to do the profiling, assigning the GenericSchema as the source but allowing source to be replaced.

- Execute the workflow via REST API which will provide you with the option to replace the source with another dataset.
- Example 1: if you executed the workflow with a dataset that only has col1, the profile export you will get will only contain col1.


- Example 2: If you executed the workflow with a dataset that has col1 populated, but null values for col2 and col3, the profile export you will get will contain all 3 columns but with Completeness at 0% for col2 and col3.
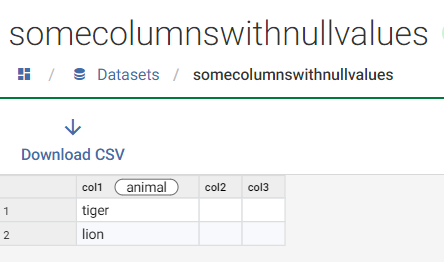

Note: If you did it this way, you may want to insert an additional Transform Step prior to the Export to exclude the rows with Completeness = 0%
- Example 3: If you executed the workflow with a dataset that has col1,col2,col3,col4, then col4 will be excluded since it does not match any columns in the GenericSchema.


1
Comments
-
Documentation on creating a reusable workflow
0
