Extracting a specific piece of information from an address using regular expressions and lookups

Data Studio has several built-in functions to allow you parse strings of text and extract a particular substring that contains the information you need. A common example would be to extract a postal code, state or country from a postal address, where the whole address is a single comma-separated string. Typically this information could then be used for tasks like segmentation analysis.
This article explores several different techniques for doing the job. Some of these techniques use Data Studio’s regular expression (regex) functions, and you can find an introduction to those in an earlier discussion post.
The ideal solution in the case of postal addresses would be to use the Validate Addresses step in Data Studio, returning elements for a validated address in separate columns using the component layout. However, Validate Addresses is does not have complete global coverage and does require additional licensing, so it’s useful to have some alternative options.
Simple extract matches on a zip code regex pattern:
Using the Parse By Regular Expression function we can return matches to a specified regular expression
To find the zip code we try to identify and extract a five-digit number from within the address string. The regex [0-9][0-9][0-9][0-9][0-9] would match to any five digit number, and so we can use the function like this:

This approach works well in some cases, but as you can see in rows 5 and 6, our function is picking up street numbers as well as zip codes:

Selecting a particular instance of the match
In the case where the Parse By Regular Expression function finds more than 1 match, these will be returned as a comma-separated list. Data Studio has functions that handle lists in this format, so if we already have a rule for which element to pick, the process is easy. In this case, we should always pick the last matching 5-digit number found, as this is going to be the Zip:

In the above example, we simply reverse the list and then extract the first item in the list. Reversing the list has no effect on lists of 1 (in other words, where the parse function only funds one match), but where more than one match is found it brings our Zip string to the start of the list, making it easy to extract.

Note that it would also be possible to define a regex to do this.
Selecting a string using a more advanced regex
More complex regular expressions can give you much greater control over what string matches you can extract. By using the regex \d{5}(?:[-]\d{4})? We can optionally select the 4-digit zip+4 code along with the 5-digit zip code:

Extracting a match from a domain
While some address elements, like zip, have a well-defined structure and are easy to extract using regex, other elements are better identified using a lookup to a known domain.
For example we can use the Extract Matches as List function to identify US state codes by looking up to a defined domain. Our domain will be a data studio table that looks like this:

By using this as the lookup table in a Transform step, we can define the function as follows:

The Match Type and Input Type options allow you to configure how the matching will behave, and whether the input is tokenized by spaces, commas, or whether we want to match the whole input. For more information see the user guide’s description of this function.

@Clinton Jones has written up another example of using the Extract Matches As List lookup to extract a country name here, which is well worth a look
Comments
-
@Clinton Jones there are a couple of ways you might be able to deal with this.
Where you have multiple elements in a single field which are space-separated, turning these into a comma-separated list can be a good start, allowing you to deal with the elements using the approaches described above. Using the Split function, with 0 as the element to return, will give you all list items

Results is:

If you use the regex from above (
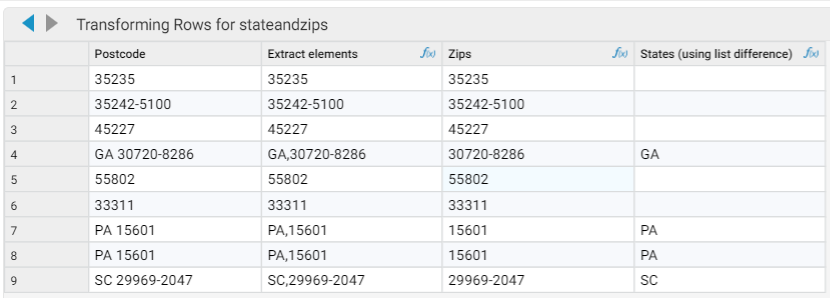
\d{5}(?:[-]\d{4})?) in the Extract Matches As List to get zips and +4s out into a new column, here's an interesting way to get the remainder (the state in this case) out of the string without doing a lookup on state code: I've decided to use the List Difference function to pull out the values that remain once the zip (which we've already parsed out) is removed. Here I do:
The result is shown in the final column below. We haven't needed to use any regex or lookup to generate the state, we're just picking what's left when any Zip data is removed. Obviously you could go on to validate the state (try the Contains Match function for this)
If you have more than two elements in a single column to split out, the process will be similar to above but there will be more iterative steps to acheive the result you want.
2