Word Frequency

Every now and then a scenario crops up where it'd handy to know how often a given word occurs within a given dataset. For example you're profiling a reasonably standardised list of values (e.g. job titles) and you want to identify unusually common terms (like 'manager' 'executive' etc) or infrequent ones (like 'test123'). You may also want to perform this type of processing to generate lookup tables to be used for standardisation/cleansing/validation later on (e.g. company terms from an organisation name field, product groups from a product name column etc).
Alternatively you may just want to do this to perform some analysis to achieve something like a word cloud:

Either way, I've recently had a stab at creating this and wanted to share the results with you, not only as this is something which I believe can be used in a variety of different situations but also because it highlights a bunch of features in the product, some alternative approaches and may be an interesting article for self-learning purposes too.
I've tried to summarise it all below, please do pop me a comment with your thoughts, suggestions and if you found this useful and would like more content like this?
1) Start
In this example I'm starting with a single column of data containing a list of company names (and I want to find the most common words in this list)

2) Standardisation
First I tidy up the data a little using a combination of remove noise (to strip special characters) and then upper case (to remove case variation between the remaining words). At this point you can also easily remove numbers too if they're not of interest to you.

3) Separate out words
Next I split out the words into individual fields (up to 20x) and I did this with a Text to Columns step (note this is a non-native workflow step but is available free of charge, to learn more reach out to your Experian contact):

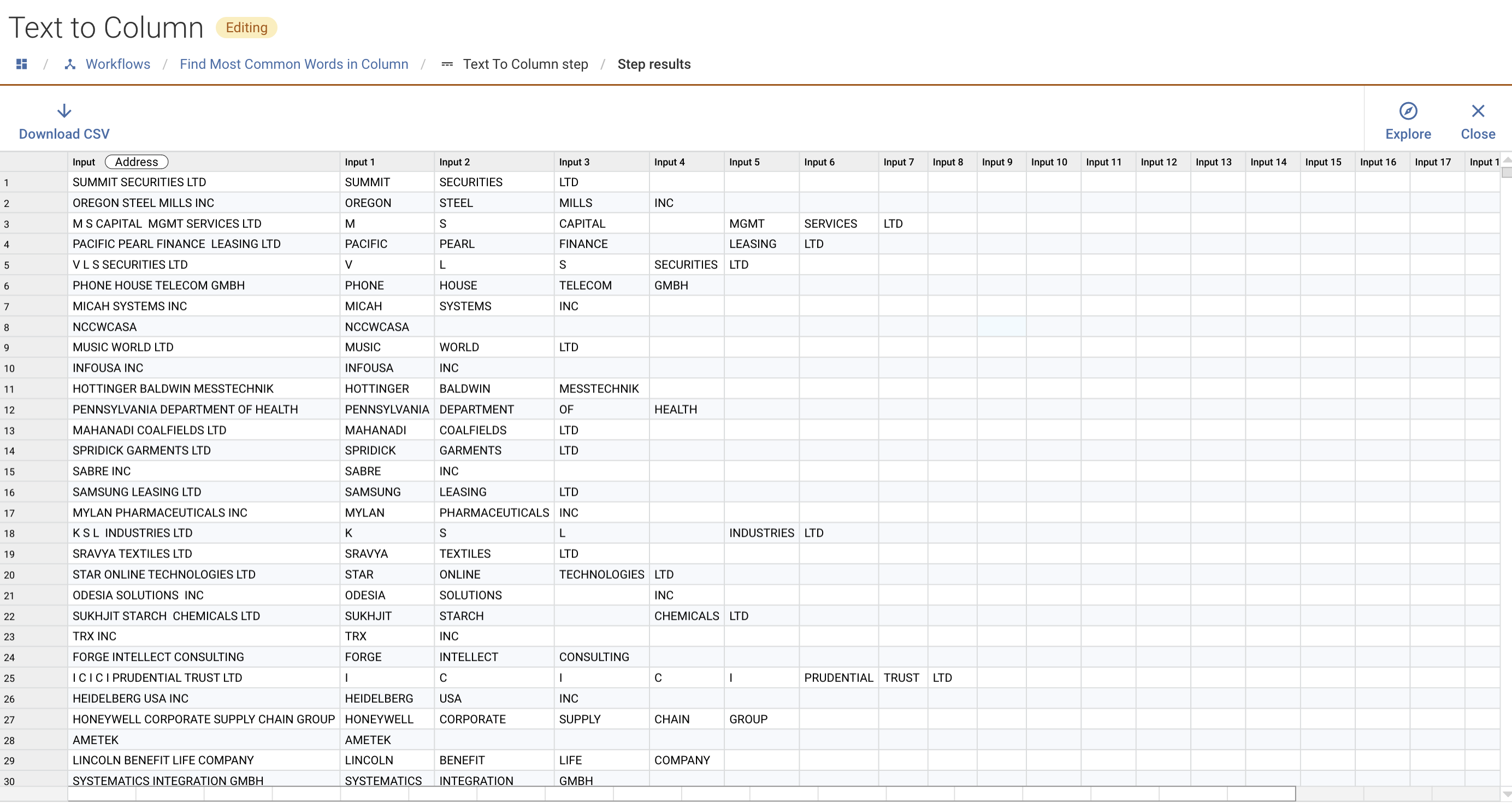
Note that this can also be achieved using a native Transform step and the 'Split' function to explicitly extract each term:

4) Columns to Rows
Next I use the new Columns to Rows step to take each of these new columns and essentially stack them on top of each other to create a giant list (note as I've split the data into 20x columns there's now a lot of empty rows):

5) Finishing touches
Then I use a simple filter step to remove empty rows, I group on the 'word' and append a count before finally doing a sort to get the desired output:


The magic bit...
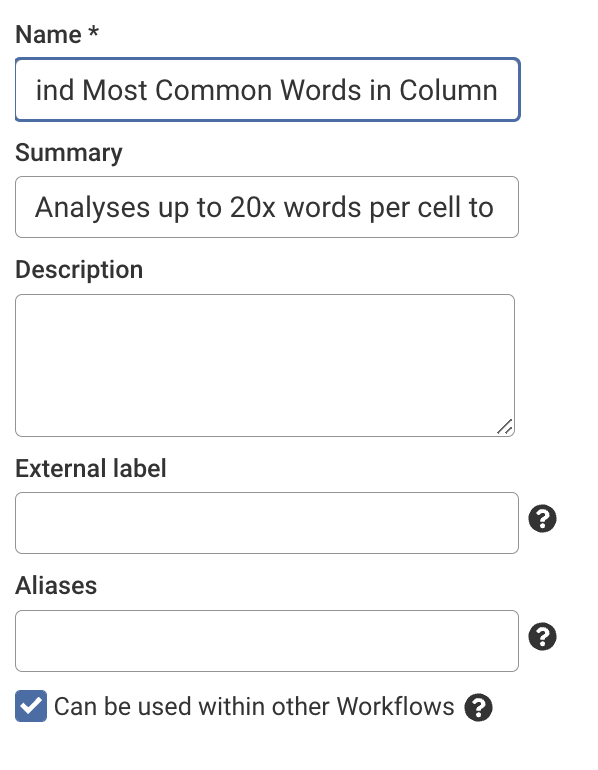
Once I'd got this working for my initial dataset I wanted to make this reusable to be easily used in other workflows. This involved 3x minor tweaks:
Part 1: permit the source to be provided at run-time (this allows this workflow to be dynamic and simply have a different source configured at run time which is pretty handy on its own)

Part 2: adjusting the workflow details to check the 'can be used in other workflows box'
Part 3: put an 'output' step on the end (so that the results can be passed to further steps and surfaced within another workflow)

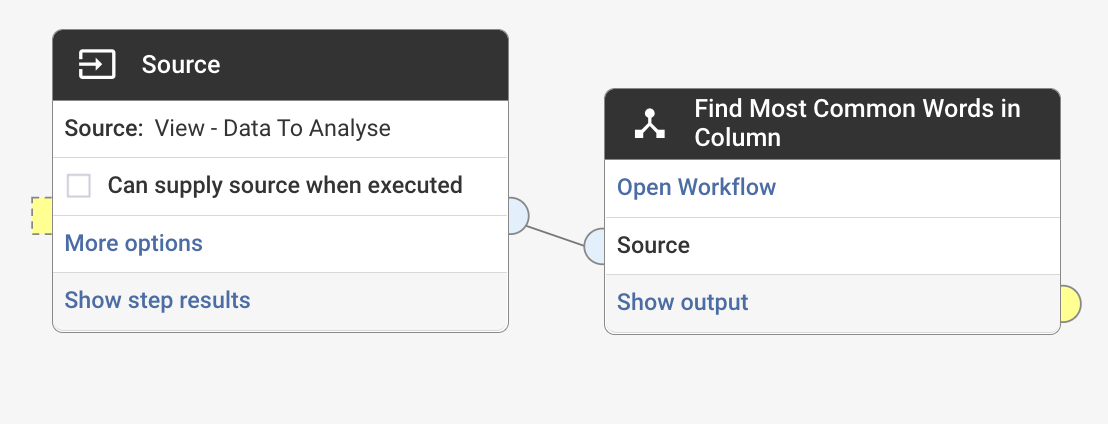
A final test
Last I tested it being used as a step within another workflow which worked a treat:

Like a copy?
For those of you with the 'text to columns' step already setup, you can simply import this into your space using the below .dmx file, alternatively I'm hoping the above steps will be suitable to help you build something similar yourself.
If you've not already had a go at using 'reusable workflows' I'd strongly encourage exploring this as it's a really powerful feature which can really help scale a more standardised approach to processing your data.
Feedback
I hope you found this post interesting/useful, let me know your thoughts below in the comments!
All the best,
Danny
Comments
-
An alternative apporach to this task is covered in the below post which avoids the use of custom steps and caters for the requirement with standard Aperture functionality:
0