Find Duplicates with Phonetic Comparators

We now have the new phonetic comparators (Soundex, NYSIIS and Double Metaphone) for Find Duplicates that you can use to supplement the edit distance comparators (Levenshtein, JaroWinkler) for better match results.
Why the need to supplement the edit distance comparators?
Edit distance algorithms count the number of steps it takes to transform from one value to the other. These algorithms takes care of minor spelling variations or typos. However, they are not effective in recognizing words that sound similar but are spelled quite differently. For example, compare Jean and Gene.
When pronounced in English, these names may sound the same, but have a very low edit distance percentage and will not likely be recognize as a match. This match can be captured by the Double Metaphone phonetic algorithm.
Which phonetic algorithm would we recommend?
The answer really is that it depends on the data you are trying to match and the degree of tolerance for false positives. While there isn’t a one-size-fits-all approach, I’ve summarized some findings here from a few references that will hopefully help you make a better decision on which algorithm to use. If you have used these comparators yourself, do share with us your findings too.
Overview of Soundex, NYSIIS and Double Metaphone
- Soundex is the First phonetic name matching system developed more than a century ago. Was initially designed for American names. Both NYSIIS and Double Metaphone were built to improve Soundex.
- Work on alphabets only. Numbers and special characters are not compared but the placements of such characters may impact the encoding of the alphabets.
- Based on sounds of letters or phonemes, so any spelling variations that causes a change in the sound will not be addressed. For example, Smith and Msith will not be matched with a phonetic algorithm because the sound of "Sm" and "Ms" are not the same
- All three algorithms have their weaknesses but are commonly available as options in products that offer duplicates detection. Research suggests Double Metaphone is recommended for general purpose phonetic matching, Soundex for Surnames, and NYSIIS for street names. However, this is highly dependent on the dataset and may not conclusive.
Soundex
- Must consider the first alphabet when encoding. Once the first alphabet is different, the records will not be considered as possible match. For example,

Catherine and Katherine are common names spelled with a different first alphabet, so they have different Soundex codes and do not match.
Due to this weakness, some culturally diverse names that sound the same are not identified as as match.
- Other than the first alphabet, Soundex uses a fixed sound to letter to code mapping. It does not cater for any other spelling differences not covered by the mapping and may also reveal some unexpected matches.

For example,
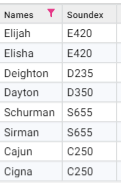
Elijah and Elisha are matched because Soundex assumes the alphabet j and s shares the same sound.
Deighton and Dayton are not matched. Vowels are ignored and the letter g does not map to the same code as y.
Schurman and Sirman can be matched. This may help discover matches that are not very obvious. Note that Soundex has other rules where similar sounding letters are encoded once only, so Sc can match with S.
Even Cajun and Cigna are matched due to vowels being ignored.
- Encoding for Soundex is limited to a 4 character code. Codes longer than 4 characters would be truncated. Variations at the end of the string may suffer from this. For example, Van der meer is matched to Van der berg. Al Fonso is matched to Al Fondue.

- In general, research has indicated that Soundex may yield a high number of false positives. However, the impact should be considered among other match criteria. For example, if you are matching based on name and address, even if the names were matched in error, you will still not consider the records as duplicates if the validated addresses do not match. As such, the risk of false positives may be lower in this context.
NYSIIS
- Attempts to improve on Soundex to cater for large number of European and Hispanic names.
- NYSIIS attempts to do some specific conversion for the first characters. For example, this takes care of matches like Katherine and Catherine, since K is mapped to C. There is consideration for mapping 2 or more letters and not just the first letter or a single letter. For example, this takes care of matches like Phillip and Fillip.· However, like Soundex, NYSIIS still fails to match Tchaikovsky and Chaikovsky or Seline and Celine.

- Another improvement is where NYSIIS also preserves the vowels rather than drop them. For example, it can differentiate values like Cajun and Cigna and so would avoid some false positives.
- NYSIIS allows up to a 6-character code. While it may still match Van der Meer and Van der Berg, it manages to avoid matching Al Fonso and Al Fondue.
Double Metaphone
- “Double” indicates it returns a primary code and a secondary alternate code to cater for higher chances of matching some ambiguous cases.
- Caters for more English pronunciation rules and includes considerations for pronunciations of other origins such as Slavic, Germanic, Celtic, Greek, French, Italian, Spanish, and Chinese. For example, where Soundex and NYSIIS fail to match, the following values were matched by Double Metaphone.

- Successfully avoids some false positives identified as matches by Soundex and NYSIIS.

- Although it seems to be latest and most improved among all three algorithms, it has some issues not encountered with Soundex or NYSIIS. For example, certain repeated characters or the presence of space, may affect the encoding and thus causing unmatched records.

Are there any tools available to help us determine the best algorithm?
As we will need to understand your dataset better to be able to advise, please contact us for more information.
References
All of the above examples have been collated through my research where I've used referred to various articles as follows:
Overview of Fuzzy Name Matching Techniques
What is Soundex and How Does Soundex work?
Is Soundex Good Enough for you? On Hidden Risks of Soundex-based Name Searching
Performance Evaluation of Phonetic Matching Algorithms on English Words and Street Names
Native Language Identification using Phonetic Algorithms
Accuracy, Precision, Recall & F1 Score: Interpretation of Performance Measures
A Gentle Introduction to the Fbeta-Measure for Machine Learning
An Overview of the Issues Related to the use of Personal Identifiers (Statistics Canada)