The chaining effect

What is the chaining effect?
Find Duplicates in Aperture Data Studio works by identifying blocks or groups of duplicates, then comparing every possible record pair within a block based on rules to determine if they represent a single entity, represented by a cluster ID.
Depending on how you have configured the rules, you may end up with a cluster which contain records that are considerably different. This does not always indicate any issues that needs to be rectified but would require careful interpretation due to a potential "chaining effect" in action.
Let's look at this example where we have Janet Doe being associated with John Larry Doe in a cluster.

When we inspect how the match has been evaluated using the Find Duplicates workbench, we will discover that although Janet Doe was assigned the same cluster ID as John Larry Doe, they actually did not match based on the matching rules.

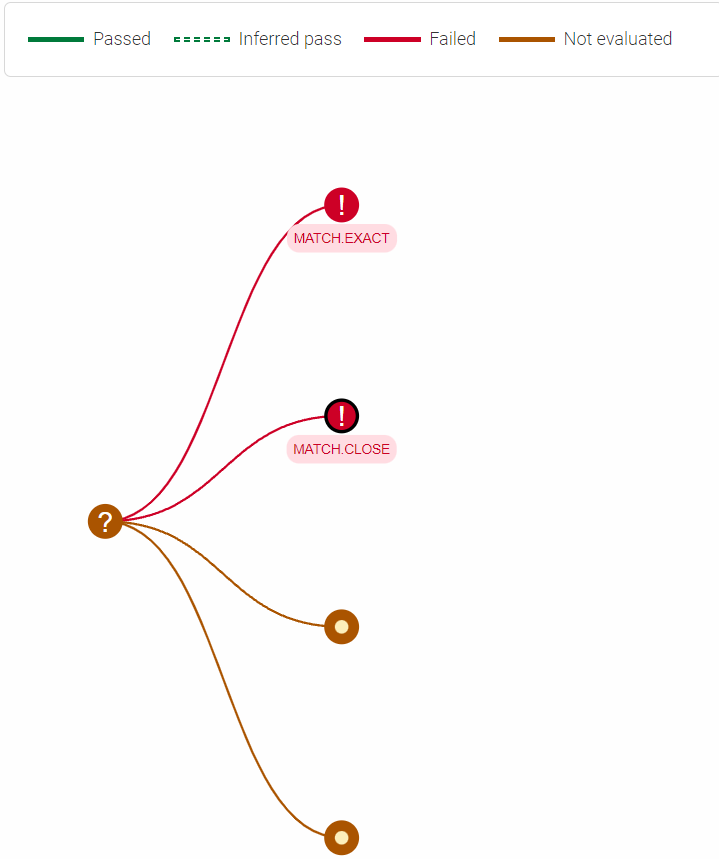
This result is expected because the rules we used required that the records should only match if:
- they are an exact match or
- an initial or initials match to the full name (InitialVsFullName) or
- all the names in a multiple-name forename match but are in a different order inverted name (InvertedNameMatch).
Forenames.Close = {ForenameCompare[InitialVsFullName] | ForenameCompare[InvertedNameMatch]}
In this case, the forename Janet when being compared to John Larry did not match because:
- there isn't a match based on initials (J & John Larry or J L & Janet)
- there isn't a match based on inverted name (Janet & Larry John)
How did this happen?
Records are put into the same cluster when they match at least one other record within a block of potential duplicates.
"At least" indicates that it is possible that a record matches only one other record within that cluster. The "chaining record" happens to be J Doe and the "chaining effect" happened when:
- J Doe is compared to Janet Doe and the forenames matches on initials (J & J).
- J Doe is compared to John Doe and the forenames matches on initials (J & J).
- J Doe is compared to John Larry Doe and the forenames matches on initials (J & J L). Note: Only requires one initial to match.
There is no easy way to resolve this even if we had to manually make a decision because J can mean Janet, John or John Larry. We can probably look to see if there is any other data available that could help differentiate the records and fine tune the Find Duplicates rules.
A simpler example
A more obvious example would be when range comparators are used in the Find Duplicates rules.
If you applied a DateCompare DayDifference comparator to allow records with +- 1 day for Date of Birth to match, you may still end up with records that have a difference of more than a day since each of the record would match another record with a difference of 1 day for the Date of Birth.

Again, this is not incorrect, but subject to interpretation. It could actually help you detect irregularities with your data. Perhaps somebody is registering for multiple accounts with a slightly different Date of Birth?
Share your story with us
Have you encountered such a scenario in your organization? Do share with us what you have done to resolve the duplicates or if you have had any interesting discoveries on your data.