Reviewing Find Duplicates Results

When you preview the Find Duplicates results, you will see the Cluster ID and Match status.
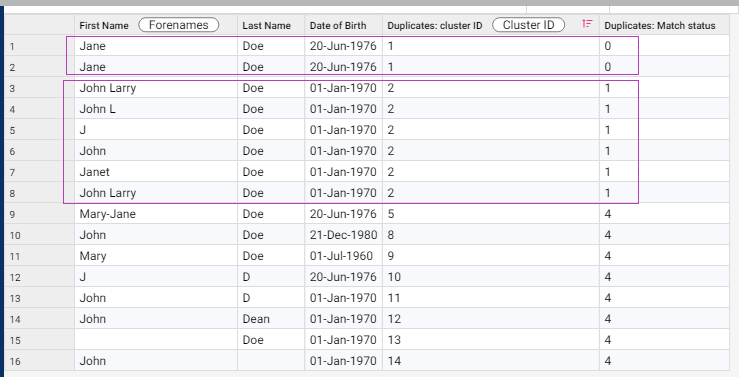
Records with the same Cluster ID are identified as duplicates. The Cluster ID is influenced by the blocking keys that determine the record comparisons to be made. However, ultimately the duplicate records and match status is determined based on the Find Duplicates ruleset.
You would also have noticed that the Match status is the same for all records within a cluster even for cases where there are exact matches and close matches (See records in cluster ID 2). This is because the Match status will always be assigned based on the lowest confidence match status of records in the same cluster. For example, even though the 2 records for John Larry Doe are exactly the same, the Match status is still (1) being a Close Match for the particular cluster because the other records like John L Doe, J Doe, John Doe or Janet Doe within the same cluster has a lower confidence match.
If you find that the clusters are not accurate, you need to check both the blocking keys and ruleset for further refinements. For example, Janet Doe and John Larry Doe are being assigned the same cluster ID, and evaluated as a close match but may actually be 2 different people.
Review Blocking Keys
- There probably isn't a problem here as the Janet Doe and John Larry Doe records have been blocked based on surname and date.
[
{
"description": "AllColumns",
"countryCode": "GBR",
"elementSpecifications": [
{
"elementType": "HASH"
}
]
},
{
"description": "LastNameBirthDate",
"countryCode": "GBR",
"elementSpecifications": [
{
"elementType": "SURNAME"
},
{
"elementType": "DATE"
}
]
}
]
Review Rules
- Given that Surname and Date are an exact match, we will then need to look at the definition for Forenames Close.
@default.country=GBR
/*
* Aliases
*/
define Exact as L0
define Close as L1
define Probable as L2
define Possible as L3
/* Match Rule */
Match.Exact={Hash.Exact}
Match.Close={Name.Close & DOB.Exact}
/*Theme Rule*/
Hash.Exact={[ExactMatch]}
Name.Close = {Forenames.Close & Surname.Exact}
/* Element Rule */
Forenames.Close = {ForenameCompare[InitialVsFullName] | ForenameCompare[InvertedNameMatch]}
Surname.Exact = {Surname[ExactMatch]}
DOB.Exact = {Date[ExactMatch]}
It may still be challenging to figure out what these records have matched based on reviewing the blocking keys and rules alone. You should also beware of the impact of maximum cluster size as well as the chaining effect. Using the Find Duplicates workbench could help you understand your Find Duplicates results better.
Using Find Duplicates Workbench
Within the Find Duplicates workbench, you will find the Compare records and Visualize Rules tools to help you understand your Find Duplicates results better.
Compare records and visualize rules
In order to know how any 2 records end up in the same cluster, we can use the Find Duplicates workbench to compare the records and visualize the rules.
First search for the records with a common value.

Then select 2 records to analyze.

The standardization results show that these records have been blocked successfully as indicated by the green highlight.
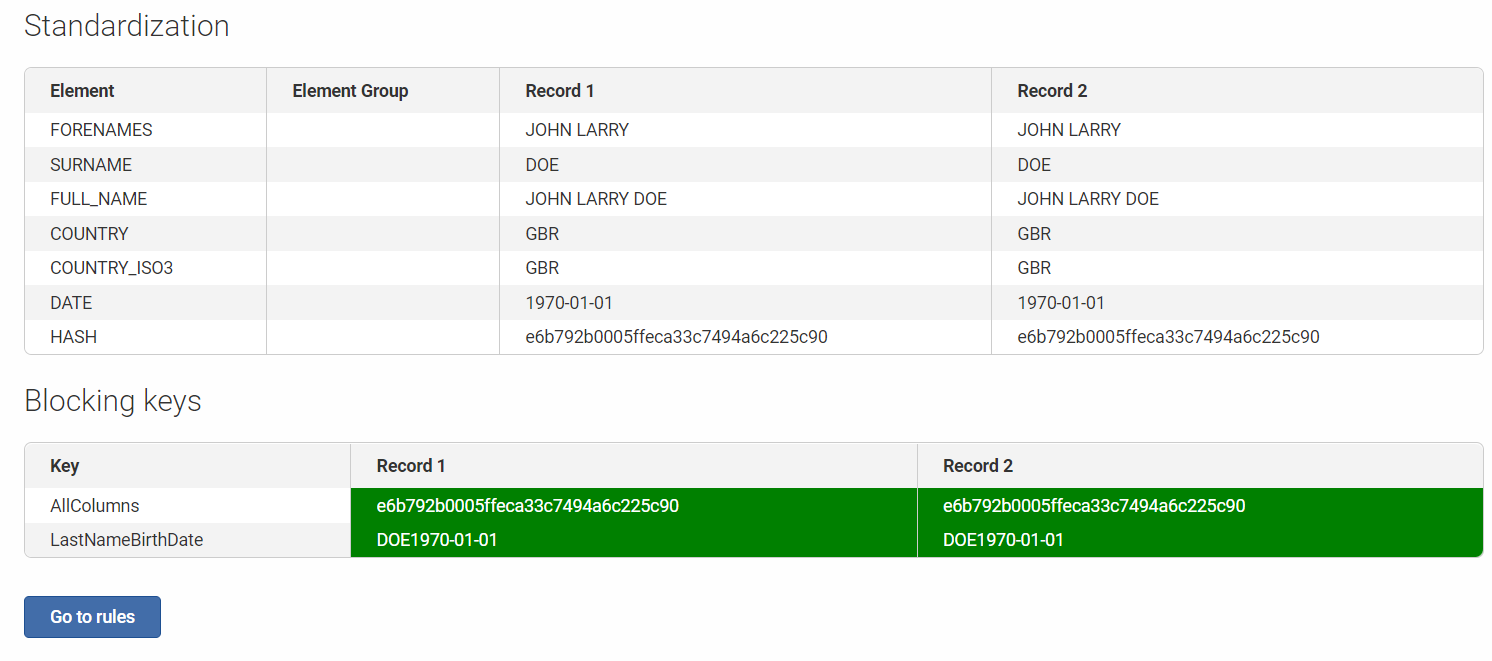
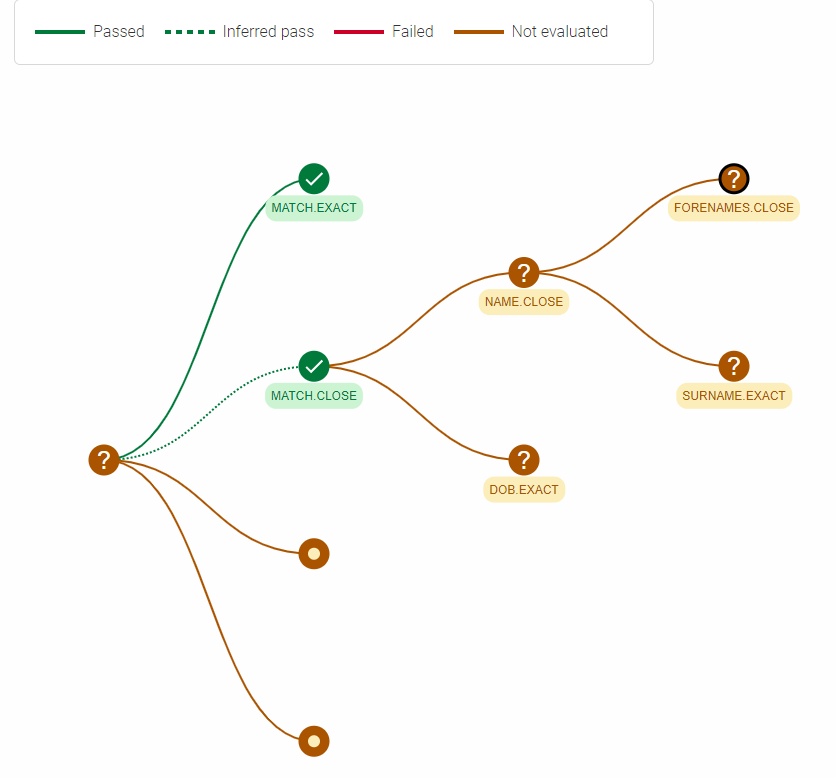
Go to rules to visualize how the Find Duplicates rules have been evaluated.

Based on the visualization, the 2 records have been evaluated as an exact match. A close match is inferred given a higher confidence match has been found. Rules are evaluated in order from L0 (Exact Match) through to the lower confident levels (L1,L2, L3), stopping at the first level that passes. Drilling down further into the sub-conditions for a close match confirms that the lower level expressions of the close match rule is actually not evaluated.