Exact match and fuzzy match with Find Duplicates Step

Aperture Data Studio offers a Find Duplicates step that runs on a powerful standardization and matching engine.
When you connect the Find duplicates step to your Source dataset, you will see that some configuration is needed before you can see results.
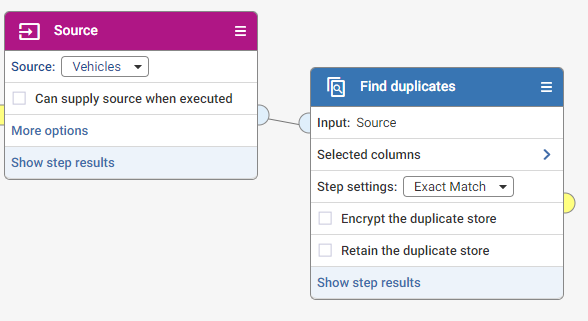
The results of the Find Duplicate step provides the Cluster ID and Match Status for each record. Any records with the same Cluster ID are considered to be duplicates. Match Status is the level of match.


Given that it is possible to define up to 4 levels of match, this enables both exact match and/or fuzzy match to take place at the same time based on how you define your rules. You have the choice on how you would define rules for each match level and how many match levels you want to use.
Find Duplicates Step Configuration
Select Columns and Tags
The Find Duplicates step is optimized for contact data de-duplication so you can see specific data tags for name components, address components, email and phone. If you are not processing contact data, you can still map the column you want to match as a generic string.
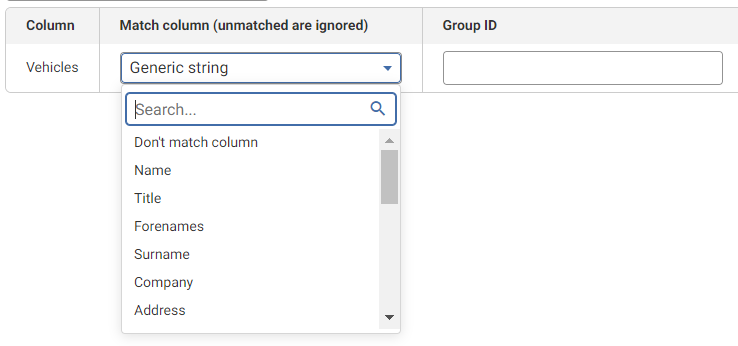
If you have multiple columns with the same data tag, you will have to distinguish them defining the Group ID.

Create/Select Find Duplicates step settings
A number of out-of-the-box settings have been provided. They are mainly to match based on name and address columns. You can choose to use any of these settings if it fulfills your requirements. Otherwise, you can create your own, especially if you are processing other data besides name and address.

In order to create your own settings, you need to be familiar with some key concepts like blocking keys and rules. Quick introduction available here.
Decide whether to retain and encrypt the Duplicate Store
The duplicate store saves the results from the Find Duplicates step. Retaining the duplicate store enables you to perform searching and maintenance operations.
Encrypting the duplicate store provides an additional security control for accessing the duplicate store.
Advanced Configuration
The Find Duplicates step is powerful because it performs better for large volumes of data and provides a wide range of advanced configuration to allow for more flexible matching. Some highlights include:

This is not an exhaustive list. There are many other comparators you can use. More details here.
Hopefully this gives you a quick summary of the capabilities of the Find Duplicates step and what you need to do to get started.