How to identify blocking keys for Find Duplicates

Blocking keys identifies records that are similar, creating blocks or potential groups of matches.
Let’s look at an example where you have a list of names and date of birth that may contain duplicates.

The rule of thumb is to be able to identify any possible chances of matches.
Which elements would you use to say that any two records are the same?
Since it is possible that people can have the same names, you would probably want to look at First Name, Last Name and Date of Birth as a combination to determine that two records are an exact match. For example:

So, the combination of all the input columns First Name, Last Name and Date of Birth could be a blocking key.
What if the First Name is not an exact match but both Last Name and Date of Birth matches?

What if the Last Name is not an exact match but both First Name and Date of Birth matches?

As you can see from the examples, the records may or may not represent the same person. Depending on your existing business rules or historical experience with your data, you may have information that already tells you these combinations are not likely to produce a potential match. In this case, it is up to you to decide whether to use any of these combinations as blocking keys.
What if only the Date of Birth matches?

On first thought, you would probably think that since people can have the same date of birth, this would not be a good matching criterion.
However, what if there are records where the First Name or Last Name is not available?
In this case, Date of Birth may be a blocking key you want to use.
How do I create the blocking keys?
Once you have determined the elements you want to include as blocking keys, you can create the blocking key following the structure as described here
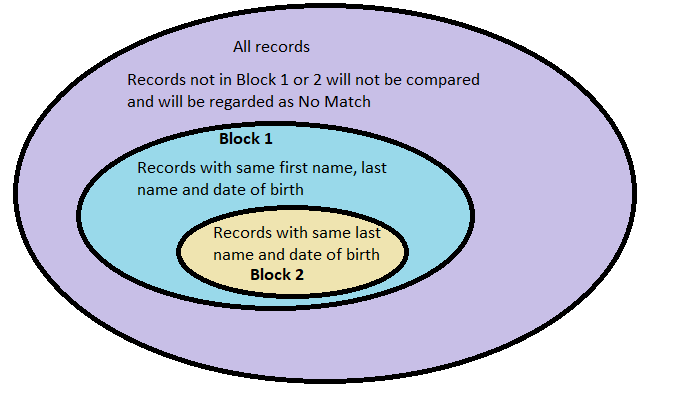
For example, I’ve decided to use the following as blocking keys:
- First Name, Last Name, Date of Birth (All Columns)
- Last Name, Date of Birth
This is how my blocking keys definition would look like:
[
{
"description": "AllColumns",
"countryCode": "GBR",
"elementSpecifications": [
{
"elementType": "HASH"
}
]
},
{
"description": "LastNameBirthDate",
"countryCode": "GBR",
"elementSpecifications": [
{
"elementType": "SURNAME"
},
{
"elementType": "DATE"
}
]
}
]
As a best practice, insert a description for each blocking key.
Country code can be GBR, USA or AUS. If your business is not based in these regions, choose the one nearest to you or the nature of your data. (Note: The country here is used to determine standardization rules to be applied to the data prior to the duplicate detection. Standardization results may not be optimized if your data is not for GBR, USA or AUS. However, it is still possible to tune your keys/rules to perform generic string matches without country-specific standardization)
Each of the column you want to use as blocking key must be mapped to an available element. You can check out the list of available elements here.
- HASH is a special element used to represent all the input columns you have chosen to match (the column must not be tagged as Unique ID). The combination of the input columns are converted into a hash value for ease of matching. A hash value is like a unique identifier for the record.
- SURNAME is the element used to represent Last Name.
- DATE is the element used to represent Date of Birth.
Once you have the correct structure, you can populate the blocking key at Step Settings > Find Duplicates Settings.
Note: Depending on the blocking keys you have created, records in a block can potentially overlap with records in another block. This does not really matter for now, and can be tuned as required later if we discover that we can do without one of the blocking keys.
Are there any other considerations when creating blocking keys?
- There are additional modifiers and algorithms you can apply to improve the effectiveness of the blocking keys. You can also analyze blocking keys within the Find Duplicates workbench.
- Beware of the maximum cluster limit.
Comments
-
Is there a maximum size for a cluster/block? and a recommended maximum size?
0 -
There is a default maximum size of 500. This can be changed in configuration if using a separate Find Duplicates server. Please remember though that the number of scores that must be stored in find duplicates for a cluster is defined by n(n-1)/2, so for a cluster size :-
500 records -> 124750 scores
1000 records -> 499,500 scores
10000 records -> ~50 million scores.
Many large clusters can exhaust storage in find duplicates, hence the default limit.
The configuration setting is :-
match.maximum.cluster.size=<number of records>
0

