Salesforce tables have different columns after upgrading from Data Studio v1 to v2

If you've previously used Data Studio v1 to load data from your Salesforce instance, and have upgraded to v2, you will have noticed that the way we show column names from Salesforce tables, and the columns we display by default, has changed.
This is because the JDBC driver we use internally to connect to Salesforce has been updated in Data Studio v2, and the Salesforce data model mapping defaults have changed.
The changes are based on customer feedback, so should be an improvement. But don't worry, if you want to revert to the v1 behaviour (for example if you have v1 workflows that you want to migrate to v2), there are some configuration options that will allow you to do that.
So what are the changes?
The first thing you'll notice is that v2 returns more columns: For the Salesforce ACCOUNT table, Data Studio v2 brings back 63 columns, as opposed to 55 columns in v1. You'll also notice that some of the column names are different. This screenshot of v1 (top) and v2 (bottom) after loading the same table demonstrates some of the differences:
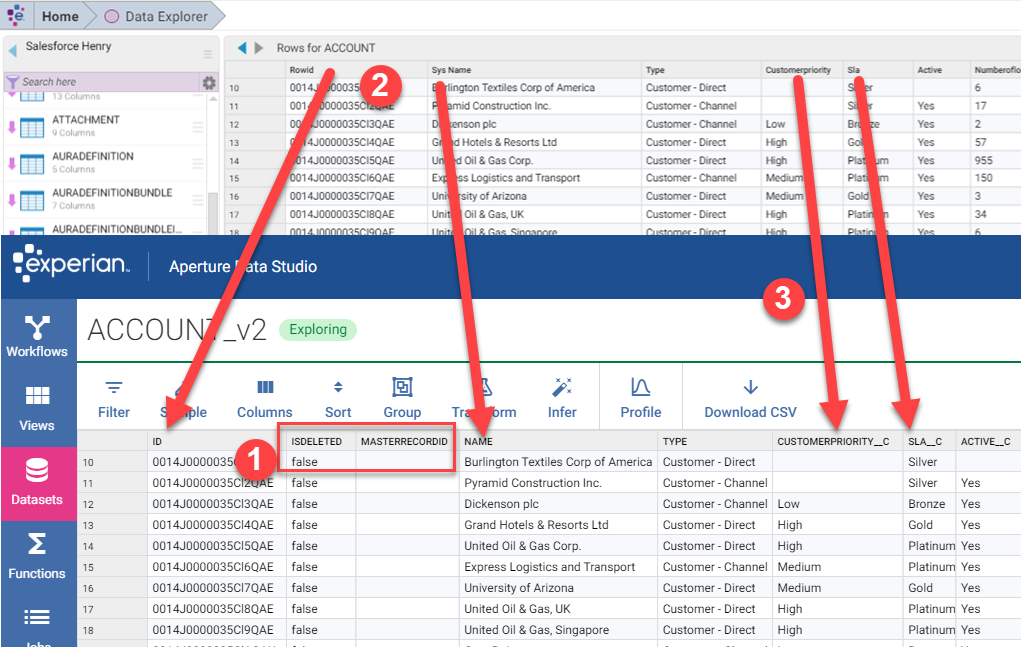
- In v2 we now expose audit fields (like
ISDELETED) and the master record ID field (MASTERRECORDID). These were hidden in v1 - In v2 we no longer change the names of system fields, but expose them as they exist when mapping the Salesforce data model. So
Rowid(in v1) becomesID(in v2), andSys Name(in v1) becomesName(in v2) - In v2 we use the "__c" suffix to identify custom column names when mapping the Salesforce data model, so
Customerpriority(in v1) becomesCUSTOMERPRIORITY__C(in v2).
Configuring the connection to change how columns are displayed
We can change these column mapping settings using the ConfigOptions connection property. This property is applied in the External System configuration page, and its value is a list of one or more options separated by a semi-colon:
ConfigOptions=(key=value[;key=value])
Used in Data Studio:

Let's have a look at the options we need to include to change v2's Salesforce data model mapping to match the mapping in v1.
Hide audit columns with AuditColumns=none
To hide the audit columns, set AuditColumns to none with the ConfigOptions connection property
Change the names of system fields with MapSystemColumnNames=1
To change the names of system fields so that Id field is mapped as ROWID and the remaining system columns are prefixed with SYS_ , set MapSystemColumnNames to 1.
Remove the custom column name suffix with CustomSuffix=strip
To remove the "__c" suffix with custom table and column names when mapping the Salesforce data model set CustomSuffix to strip
Combining all three settings
So to use all three of these settings together, the connection property to add will be:
- key: ConfigOptions
- value:
(AuditColumns=none;MapSystemColumnNames=1;CustomSuffix=strip)
Whenever you change how SF data model mapping is defined you will also need to specify a new SchemaMap property, which is the name of the file where the data model is written. You can set the value to any name you want, in my case I've used:
- key: SchemaMap
- value:
v1schema
Finally, here's v2 with the same data model used in v1:

Comments
-
I've also been asked recently about changing the casing of identifiers in the schema (column names, table names, etc), so that they're not all upper-cased in v2.
You can achieve this with another of the settings in the ConfigOptions property:
UppercaseIdentifiers=false.This setting defaults to true, but can be set to false to ensure that the driver maps objects to the mixed-case name.
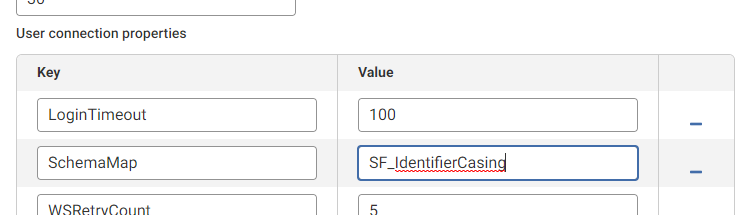
Reminder: When changing the
UppercaseIdentifierssetting (or any of the other config settings), the driver will need to define a new data model mapping, so you should specify a new value for theSchemaMap, which is the name of the file where the data model is written. You can set the value to any name you want, in my case I've used:- SchemaMap=SF_IdentifierCasing
 1
1 -
A note on using UppercaseIdentifiers set to false with a SQL Query specified for data load:
As per the Progress driver documentation, you'll need to "…enclose identifiers in double quotes and the case of the identifier must exactly match the case of the identifier name". In other words, your query would need to look like this:

If the double quotes are not used to surround the table name in the query, you'll get an error similar to:
[ApertureDataStudio][SForce JDBC Driver][SForce]syntax error or access rule violation: object not found: ACCOUNT
The quotes are not needed when the UppercaseIdentifiers setting is default / true.
0