How to systematically sample with a fixed sample size and varying population size

I was recently asked how to build a Data Studio workflow that would output a systematically sampled set of records with a fixed sample size (e.g. 1000 records), where the number of records in the input will vary. Here's my approach, let me know if you have a better one!
Requirement
We want to sample every nth record from the input data set, to produce the fixed-sized sample but ensure that the records in the dataset (the population) are sampled systematically, where every nth member within the population is recorded within the sample.
The existing Sample step does not allow for this, because the step size between sampled records has to be specified as part of the step configuration, whereas the ask is for the step size (the nth record to select in the sample) be calculated based on the number of input records and desired sample size:
- If my first batch of input data contains 10,000 records and I want to use systematic sampling to create a sample of 1,000 records, I need to set "how often to sample" to 10
- If my second batch contains 20,000 records, sampling every 10 records will give me 2,000 records in the sample. If I use the "row limit" to restrict the sample size to 1,000 then I’m only sampling from the top half of the dataset, which will not be a systematic sampling
An additional requirement is that I want to also output the balance of the records (the records that were not selected in the sample set) into another output file? Again, this is not possible using the existing Sample step.
As a reminder, here's what the Sample step offers:

Solution
Rather than using Sample, we will use a Split step based on a reusable function (used here as the filter) that takes the desired sample size as a parameter, and internally uses the Row Count and Current Row functions to calculate the required step size (the fixed gap between selected records in the population) and select records for the sample. We then assign "true" to records that will be in the sample and "false" for the others.
Here's the function that does the work:

NOTE: See comments below for an improved variation on this solution that avoids incorrect sample sizes
The step size will typically not be a round number. Consider an input file of 33,456 records and a desired sample size of 1,000. We need to sample every 33.456th row, which is obviously not possible. In rounding the step size to an integer with the Round Number function, we will cause the resulting sample to be slightly smaller or larger than the desired size. In this example, we use step size 33. This under-states the step size and so creates a slightly larger set of sampled data: 1,013 rows (33,456 / 33 = 1013.8)
Once the sampling step size has been calculated, we using the Remainder function to select rows to include in the sample, equivalent to where:
row_count modulo 32 = 0.
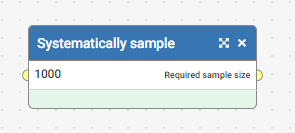
The function can then be used as a filter in a Split step like this:

Where the saved function we created earlier is used in the Split filter, with the required sample size specified
Comments
-
Hi @Sueann See . Yes, this is definitely a better approach, and will teach me for not reading Wikipedia first! By using a non-integral step size rather than round it, and then changing row selection logic to sample rows where the remainder (when the current row number is divided by the step size) is less than 1 rather than equal to 0, you avoid the problem of creating samples that are too large or too small.
Here's my updated function (which takes "Required Sample Size" as a parameter):

This solves the problem of generating samples that are too small. As for the issue of always selecting the same rows (including the last row), you could fix that I think with a random starting point that is < step size, but you would need to be careful to only generate that starting point once, and use the same one for all iterations through the "systematically sample" function.
2