Approach for Matching Product data (product description)

Yesterday @MiteshKhatri @Akshay Davis @Katya Jermolina and I were having a discussion about approaches for matching product name information using Data Studio, so I've put together the below summary of the approach in case it helps anyone else.
Before I go through the steps I want to call out that there are a variety of different approaches you can take depending on the dataset you're looking at including: (1) using the rules-based fuzzy-matching engine Find Duplicates step, (2) building your own 'blocking' keys and then doing a self-join on records that 'block' together from which scoring can be done (e.g. edit-distance calculations) on candidate pairs or (3) using a transform step to build a 'match key' which can be used to group together records.
Either way, I'd encourage a focused approach to discovery/profiling of the data before diving into any matching tasks.
Product Matching Example
In the above example we're focusing on a field which has some consistent information held within it, but the order of these values and presentation of them alter from one record to another. Also this same approach is useful if your data appears in different fields in one source (e.g. product, size, quantity) but you want to match it to a dataset which has this information stored within a single string.
For this article, I'm using an illustrative example featuring the below fizzy drink products:
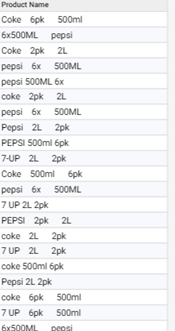
Define match elements
The approach we discussed yesterday was to identify common features from within the data which i would want to match on. In this case it would be product name, pack size & volume per unit (but in your data it might be: colour, dimensions, material etc).
Extract match elements
Once these 'matching' characteristics are defined we then want to build transformation logic which extracts the relevant information from the input string into a standardised form:
In this example a combination of techniques are used for each element, based on what I learnt about the variance of the data from profiling activity. Some of these rules include: standardisation of special characters (e.g. 7-up and 7 up), lookup tables to extract values known to be products (or you might do the same for 'colours') and regular expressions to pull out values that conform to specific patterns (e.g. pack size and volume per unit.)

Note: this may take a bit of iterating, so profiling the output of this is also a good idea to get to a point where you're comfortable with your definitions.
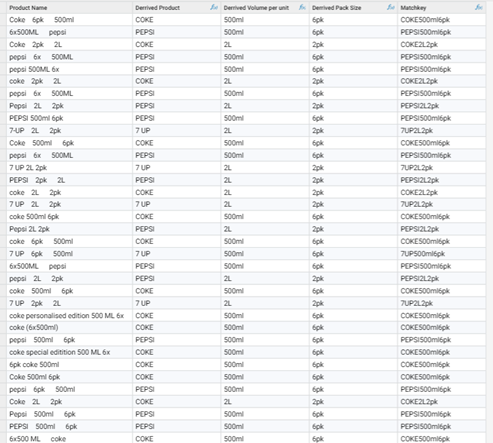
Create a 'matchkey'
Next simply concatenate the elements together to form a match key (in my case I used a 'remove noise' function on this key to help standardise this key a little further):
Review results
Next I then created another field to count the number of matches in each cluster (i.e. where they shared the same matchkey).Then sorted my table on the count and matchkey fields:
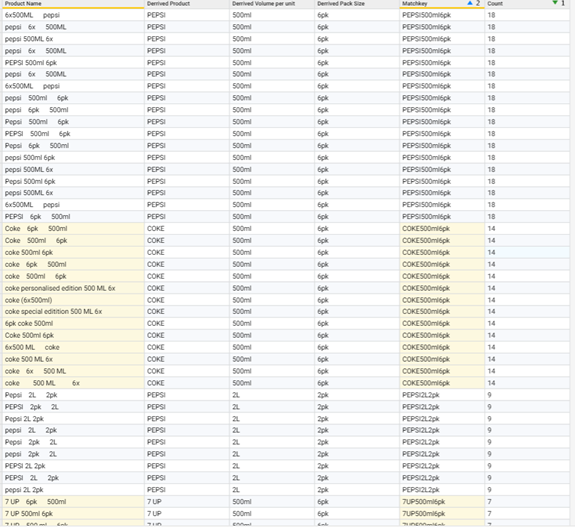
As you can see, the above approach has helped me cluster together records which share similar characteristics and I can then take this list through further steps to 'Harmonise' them to a common value (or define a new one using a Transform step), extract unmatched information to perform further profiling or even to output this list (and the workflow report) for review before committing any changes.
Disclaimer
Note, as with all matching, the best approach to take will vary depending on the data you're reviewing and the unique set of challenges presented in the way that the data varies in format, structure or consistency.