Partition Values (Dynamic SQL Partition Row Number)

A question that's cropped up for a couple of clients recently is how do I segment my data and split/partition it?
Sample Data (Starting Point)
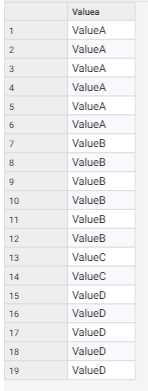
In the above example I have records which I'd like to split or partition based on a value in a specific field (this could be a category, source, date etc). Before I go through the steps to do this, I'd like to call out that this only works if the data is ordered by the values in the partition field (if not, apply a sort).
Steps to create a Partitioned Row#
1) First I use a Transform step to add a new field containing the 'CURRENT ROW'

2) Then I use another Transform step to perform a lookup to determine the partition rows
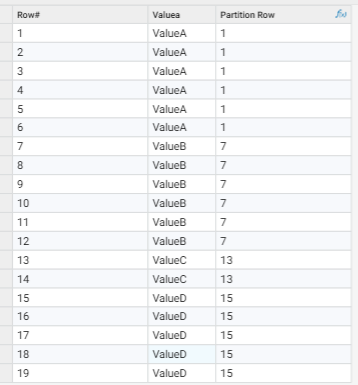
3) Finally I run a simple mathematical calculation to create the Partition row#

I've attached a sample workflow and dataset that you can use to take a look at the above in your copy of Aperture Data Studio:
https://us.v-cdn.net/6031645/uploads/808/G2SH3HIF3LBQ.wfl https://us.v-cdn.net/6031645/uploads/992/WG36MPCTEHTD.xlsx https://us.v-cdn.net/6031645/uploads/383/3NXWUZ13AYJ9.mp4Example
I recently worked on a large dataset that contained millions of records, and within here there were rows from different suppliers/sources (this was represented with a supplier number). And I was trying to create a sampled subset of this that contained no more than 100k records per supplier. So I used this approach to create a partitioned row# and then performed a filter where that new field was <100k.
What do you think?
Please comment on here if you find this useful / helpful including a little bit of a description on why you were looking to do this.