Ensuring you always return the same duplicate ID with Find Duplicates

Find Duplicates returns consistent Cluster ID after each run. Consistency here applies to the sequence order of the input file. So if the same file is submitted to Find Duplicates, in the same order, then the Cluster ID will be the same on each run.
In some cases you may not be able to guarantee the order of the records being received but still want the same IDs generated after each run, unless a cluster has been merged or split due to a change in a linking/bridging record.
Here we will demonstrate how to assign an identifier to each record, which will persist through reprocessing in any sequence order, or with the addition of new records. We will refer to this identifier as a persistent ID.
Note: All workflows were built with Data Studio 1.6.0, please check the release notes for backward compatibility with the version you're running.
Properties of a good identifier
1) The ability to recreate the persistent ID with no prior processing knowledge
Each record will require a unique identifier, which will be used in determining the persistent identifier for the cluster. This ensures that a property of the record itself can be used to generate the persistent ID, rather than any prior processing knowledge. Using a unique ID for the record also ensures that this does not change even if other fields within record, like name, address etc., are updated.
2) Time based and ordered
Within a cluster or records we want to ensure that a method exists to always select the same ID as the persistent ID for the cluster. The simplest method for doing this is to assign each record an ID which tracks the order in which the records were created, and orders them. This way, we can select the lowest record ID as the persistent ID for the cluster.
The simplest example, where only data from one table is being processed, would be to use an AUTO INCREMENT ID.
If the data is coming from multiple systems, or you are unable to assign an AUTO INCREMENT ID, then an ID can be generated within Data Studio, which will order records by the first time they were seen or processed. A transform step with a new column calculated as shown below will satisfy this requirement.
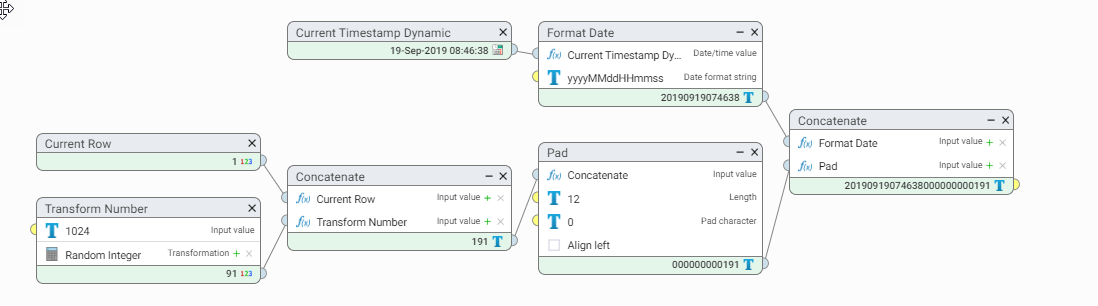
We use the date and time, but since we can process thousand of rows a second, we append the row number as well as a random integer.
3) Globally unique
The last attribute we require for an ID is one that we can guarantee to be globally unique across all the data sets we will be linking. If there will only ever be one, this is not a problem. However, if new data sources are likely to be added, the safest option is to generate a new globally unique ID within Data Studio.
The method shown above will do this if only one instance of Data Studio is being used and only one or two workflows will be ingesting data.
If multiple instances of Data Studio are being used, across multiple sites, a more robust and distributed method. A custom step is available which implements a variant of the Twitter Snowflake algorithm to solve this. Contact your account manager if you require this step.
Assigning a persistent identifier
We will assume that all records are coming from a single source system and that we have an auto increment ID assigned. To demonstrate this behavior I have used the GBR Find Duplicates Sample file and a randomly sorted version of the same file. I want the same persistent IDs for both files show below

When each of these files are run through Find Duplicates, the cluster IDs will be different for each cluster, as the sequence order has changed between them. The simple method for creating a persistent ID, is to choose minimum record ID for each cluster and then join that back to the original records.
To select the minimum record ID, we simply group on the Cluster ID, and then add a new aggregate column called "Persistent ID" which is the minimum value of the "Record ID" column

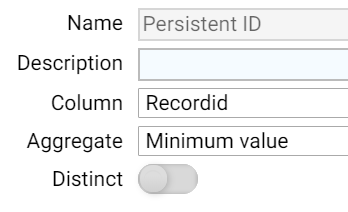
We then perform a join the result back to the original input to append the Persistent ID to each record.

If we sort on the Persistent ID for both the original and randomized version, we can use a Multi-View to compare the results and see that they are both the same.

This full workflow, using the files above, is here
Determining changes to commit
When processing a source through Find Duplicates which may have had additions, updates or deletions, it is possible that existing persistent IDs will change. A new or updated record may bridge or link two existing records, merging the two clusters. Similarly, an update to or deletion of a linking/bridging record may cause two previously linked records or clusters to now split.
In each of these cases, more changes to IDs may be required than the records added/updated, but with large data sets we may not want to update all records.
The process to determine this is simply a case of comparing the Persistent ID as supplied, with the new one generated.
If we take the following example, which is a subset of the GBR Find Duplicates Sample file.

Using just the GBR Indvidual Default rules, which don't take into account Email or Dob, we find a loose match between these four records.
If we now receive an update for record 123493, as shown below, we would want to only update the IDs where the cluster ID has changed.

When we process this file, we rename the Persistent ID column to Original Persistent ID and process the file as previously discussed, assigning a persistent ID. We then compare the new ID to the old, and filter for records where they are not the same.



Which, in this case, gives us a single record.
