Using a discriminant for Find Duplicates clustering

Find Duplicates will use fuzzy matching to link records, however, in some cases you may have a discriminant field you wish to use to break clusters. In this post we cover how to make use of these within a workflow.
The simple scenario
In this scenario, we are processing transaction records and matching on name, mailing address and e-mail address. E-mail address is the key field we want to use to identify a customer is the e-mail address. We also have some customers with individual verified accounts, identified with an account ID, and do not wish these to grouped together and to use the account ID as a discriminant field.
In the example below, only using the Name, Address and Email fields to match on would result in these two records to be linked, even if at a low match quality.

We can see that each of these transactions have a separate Account ID, and wish to ensure these are never automatically linked.
Step 1: Add discriminant to match rules
The first step is to modify our match rules to only match where two records have the same account ID (ExactMatch), only one has an account ID (OnePopulated), or both do not have an account ID (NonePopulated). We will map the Account ID as a Generic_String and use the following new AccountID rule:
AccountID.Exact={Generic_String[ExactMatch,OnePopulated,NonePopulated]}
We then update the existing top level rules to test for AccountID.Exact as shown below
Match.Exact={AccountID.Exact & (...)}
Match.Close={AccountID.Exact & (...)}
Match.Probable={AccountID.Exact & (...)}
Match.Possible={AccountID.Exact & (...)}Where (...) represents the existing match rules.
A more complicated scenario
Running with these rules account for the simple cases described above, where pairs of records have account IDs. However, this will not handle the case shown below. In this scenario, a father and son have the same address and e-mail address and use a similar name.
Given records 5 & 6 below have different account IDs (A97851Q04 and A97851Q05) we do not want these two records to cluster together.

Part of the power of the Find Duplicates step is the ability to use linking records to cluster groups of records together based on varying information. In the example above, record 7 will match to both records 5 and 6 based on the name and e-mail address fields, even though records 5 & 6 don't match to each other. To do this we need to extend our workflow.
Step 2: Breaking clusters within a workflow
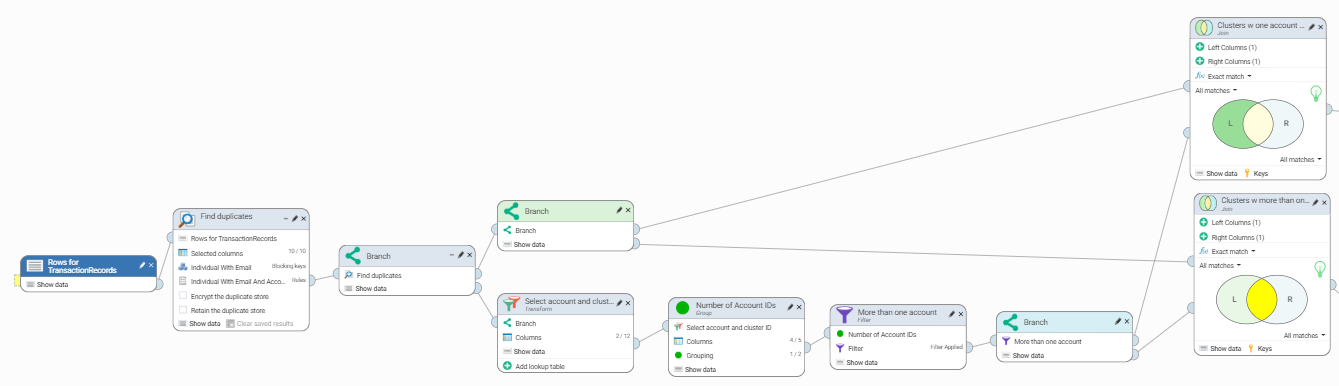
Step 2.1: Identify clusters which contain multiple account IDs
First we will determine which cluster IDs contain more than one account ID. Since the only columns we're interested in are account ID and cluster ID, it is good practice to transform the data to only use the columns we need.
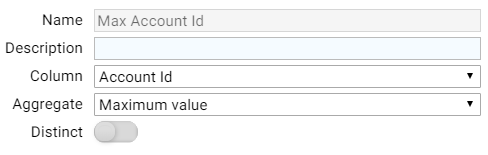
We then add a group step to group on the cluster ID and calculate the number of Account IDs within the cluster (Count excluding nulls - Distinct), and the largest account ID (Maximum Value).


We then add a simple filter to select only the cluster which have 2 or more account IDs associated.

Giving us the following steps

Step 2.2: Split the records which need to be reprocessed
Now that we have determined which clusters have more than one account ID, we need to split these out for re-processing. To do this we perform two joins on the initial data. In both cases we join on the Cluster ID, but we perform a left outer join to keep records with less than two account IDs and an inner join to keep records with two or more account IDs. These can be union-ed at the end to return the full file.
The workflow will now look as shown below
Step 2.3: Append a new sequence ID
With the records to be reprocessed, we will now create a new artificial sequence ID to be used as a discriminant. This is to allow for the following:
- All records with the same account ID should still be clustered together
- Records without account IDs should be associated with one account ID if possible, or against each other if not
To do this the sequence ID is simply the original cluster ID concatenated with either the account ID if one exists for the record, or the maximum account ID for the cluster if one doesn't exist.

Step 2.4: Re-run Find Duplicates and create new cluster ID
This new sequence ID will replace the account ID as the discriminant in a second run of Find Duplicates. Since this is only being tagged as a Generic_String, with no element group, the same rules and blocking keys can be used again.

We then add a Transform step to update the Cluster ID by appending the Original Cluster ID and the new Cluster ID. This ensures the ID we generate is unique, and you are able to link the records again should you wish to query for the larger potential cluster when running a manual review.

Step 2.5: Combine final results
Unioning the results of 2.4 with other join from step 2.2 gives us the final output.

This gives both the ability to use a discriminant and also trace back the original cluster where there was ambiguity, if a manual review is required.
Comments
-
@Clinton Jones yes, as long as the element exists within your source data you can use it in this way. The workflow as supplied in this post may need to be updated if you were to consider ages or dates as you may want to consider ranges or buckets for comparison rather than individual values.
1