Tips to improve workflow performance

If you ever find that a workflow is taking a long time to execute, you might want to think of ways to improve it. Below are some practical tips and examples that will help you to achieve the best performance out of your workflows.
Workflow Structure
First of all, it is advisable to break down large workflows into smaller ones, so that they can be executed in parallel.

Above is an example of one workflow that contains 3 distinct parts. Each part starts with an import and ends with a snapshot step without any interdependencies. If executed, each part of the workflow will run in sequence one after another. Create a separate workflow for each of the distinct parts and all three workflows can be executed in parallel. In the example above, 25% improvement in performance was achieved by splitting a complex workflow into 13 distinct workflows and running them in parallel. Use scheduling tools or scripts to execute workflows in parallel or in sequence as required.
Reduce the number of records being processed as early as possible
Join and Group steps are the most performance intensive operations. Think about an opportunity to filter out data early. In the example below, the filter was applied after the join, whereas applying the filter early would reduce the number of records being passed into the Join step. In this example, 125 million rows took around 3 hours originally, but was reduced to 15 minutes after the change due to the number of records filtered out.

Hidden Columns
Be aware that any calculations or lookups that are done on hidden columns are still taking place in the background. In this example, the calculations are still performed and will slow down workflow execution despite the results of those calculations are hidden. Remove any calculated columns if they are not needed in order to improve performance.

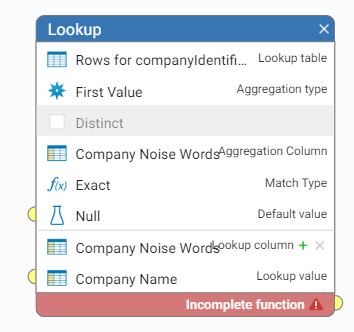
Lookups
Lookup is a powerful step but it is easy to configure in a way that will slow down the performance. For example, the default aggregation type is 'All Values' in the lookup step, which means that all values in the lookup table are scanned for potential matches. It is a slower operation than using aggregation type 'First Value'. Consider if the lookup is done on the unique value or if the requirement is to match on any of the values in the reference table. If this is the case, use 'First Value' aggregation type which is a lot more efficient.
Revisit Workflows
Workflows change all the time as new requirements emerge. It is often easier to add new steps at the end of the workflow than to rework the whole workflow structure. As a result workflows grow big and inefficient. It is recommended to revisit the workflows after the requirements have stabilised and look for potential improvements that can be achieved.
Feel free to share your own tips that you think might help to improve workflow execution!
Comments
-
Thanks Katya some really practical tips here that will be very useful on the workflows set up to run frequently.
0 -
@Clinton Jones , it shouldn't make a difference in principle. However, we occasionally saw examples where workflow performance had been slow due to a dependency on the source or target databases (either slow to import or to export data). It is always best to check that the database is accessible from the Data Studio server and there is no network latency between the database server and Data Studio. If you suspect this is the case, we usually recommend to try running the workflow with a CSV file as an data source instead of the database connection and export data into CSV instead of the database. This is simply to eliminate any dependencies on the external databases, as files and snapshots are stored locally on the Data Studio server.
If the workflow executes much faster using CSV files, it is probably due to database connectivity and is something to look into. If the performance does not improve, then there are usually other ways to improve the workflow performance, such as mentioned in the tips in this thread.
1
