A solution design for validating multiple mixed file schemas

We've recently been working on a solution to the following ask:
- A user has hundreds of data files with different schemas (different column names, datatypes, numbers of columns etc)
- Each file has an accompanying metadata file, defining expected attributes (columns, datatypes, primary keys, lengths)
- We want to be able to load all these files, and validate against the schemas, to find any issues.
- The process must be automated and scalable. We cannot manually create hundreds of Datasets or Workflows in Data Studio
We have proposed a high-level solution which uses calls to the Aperture REST API to stage the files and load into Datasets, and then to run Profile and Schema Validate workflows.
Here's some more detail on the solution's various steps:
1) Loading the metadata
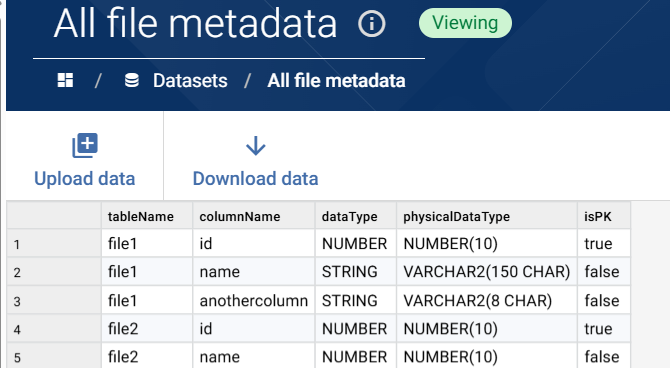
Metadata for all files is in a consistent JSON format, with attributes for each column defined. For example:
[
{
"tableName": "file1",
"columnName": "id",
"dataType": "NUMBER",
"physicalDataType": "NUMBER(10)",
"isPK": true
},
{
"tableName": "file1",
"columnName": "name",
"dataType": "STRING",
"physicalDataType": "VARCHAR2(150 CHAR)",
"isPK": false
},
{
"tableName": "file1",
"columnName": "anothercolumn",
"dataType": "STRING",
"physicalDataType": "VARCHAR2(8 CHAR)",
"isPK": false
}
]
Given the standard schema, we can load all metadata files into one multi-batch dataset using a dropzone, ready to validate against later:
2) Loading the data files
Because there are hundreds of files to load, all with different schemas, we can't use Dropzone and instead will need to create a new Dataset for each one. Instead we do this programmatically by using Data Studio's file upload (POST api/1/upload) and create dataset (POST api/1/datasets/create) endpoints.
Example input file (.csv):
id | name |
|---|---|
1 | abc |
2 | def |
3 | ghis |
4 | 123 |
5 | xyz |
6 | def |
7 | ghis |
8 | abc |
9 | xyz |
10 | ier |
Before making calls, ensure you have reviewed and understood the API Auth mechanism. An external (to Data Studio) script or integration app would orchestrate the calling of these endpoints.
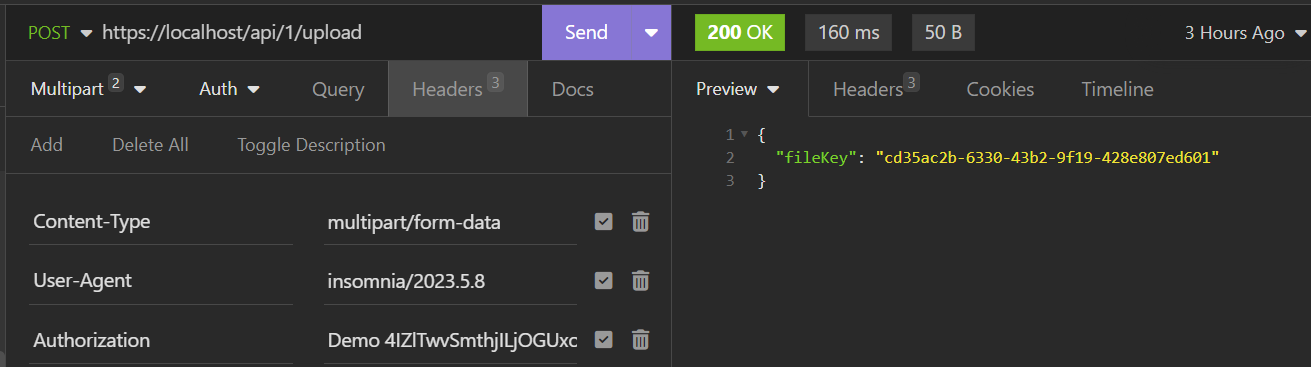
Uploading the file via the upload endpoint will stage the file in a temporary location and return a filekey, valid for 15 mins:
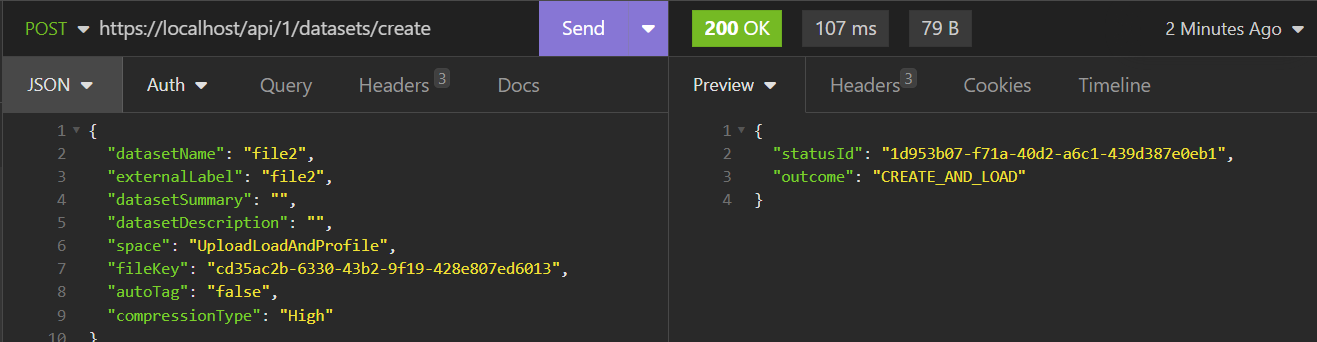
Creating the Dataset will involve passing the fileKey, and your desired datasetName and externalLabel, to the datasets/create endpoint
Request JSON:
{
"datasetName": "file2",
"externalLabel": "file2",
"datasetSummary": "",
"datasetDescription": "",
"space": "UploadLoadAndProfile",
"fileKey": "cd35ac2b-6330-43b2-9f19-428e807ed6013",
"autoTag": "false",
"compressionType": "High"
}
The API response will indicate success or error. Note that the externalLabel must be unique. For this solution, we would recommend using the file name as the "datasetName" value, to make it easier to tie the Data file and the metadata file together in Aperture when validating the schema
3) Profile and validate data against expected schema
We will not need to create hundreds of different workflows to profile and validate the schema for each unique Dataset.
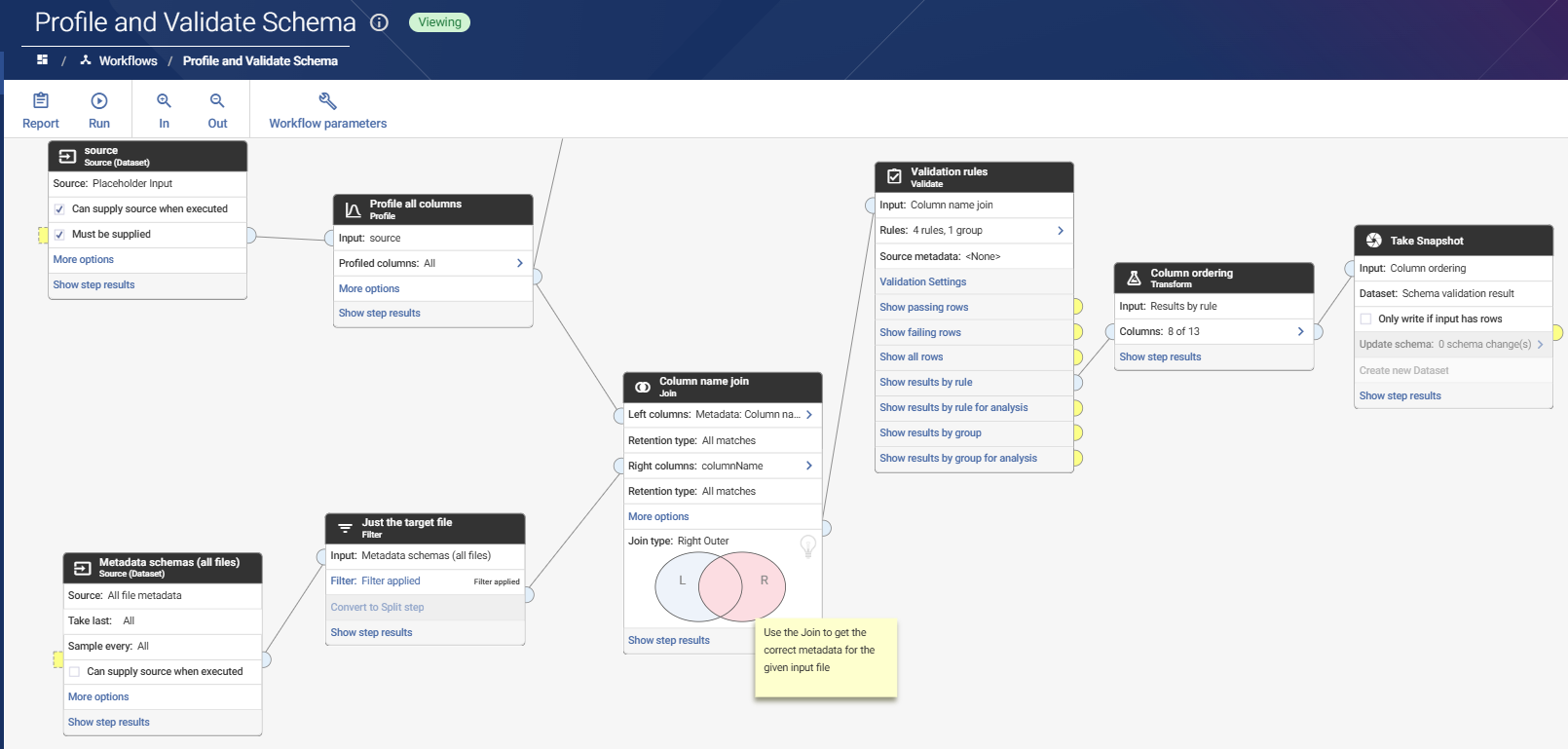
Instead, we make use of the Workflow Execution API endpoint, with the Workflow Can supply source when executed option to pass in each Dataset in turn.
Because the Profile and Validate steps will generate the same output schema for all inputs, the results for all Datasets can be added to a single multibatch snapshot.
Although the workflow below looks complex, in simple terms it profiles data and then compares that actual column metadata against the expected column metadata, defined in the metadata file loaded in step 1.
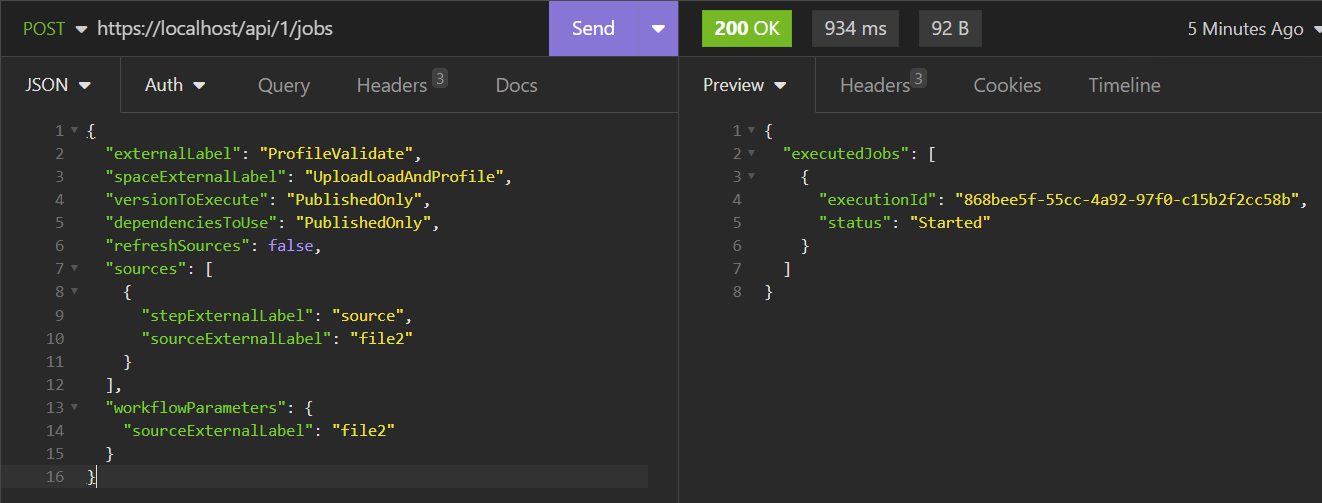
Request JSON (POST call to /api/1/jobs)
An API call to execute the "Profile and Validate" workflow will be made for each loaded Dataset in step 2, with the Dataset's External Label passed as the identifier
{
"externalLabel": "ProfileValidate",
"spaceExternalLabel": "UploadLoadAndProfile",
"versionToExecute": "PublishedOnly",
"dependenciesToUse": "PublishedOnly",
"refreshSources": false,
"sources": [
{
"stepExternalLabel": "source",
"sourceExternalLabel": "file1"
}
],
"workflowParameters": {
"sourceExternalLabel": "file1"
}
}
The workflow also uses a parameter to pass in the target file, which is used to filter on the correct metadata.
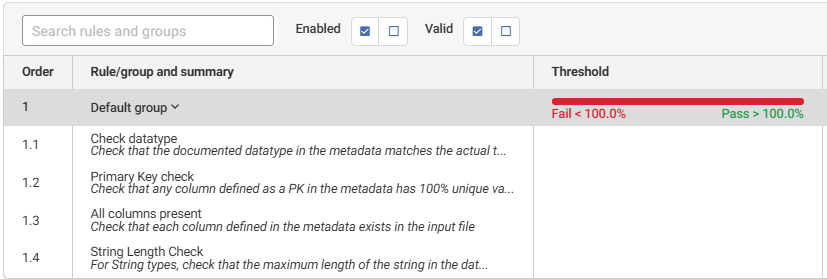
In my example I have created a handful of rules in the Validate step, but it would be trivial to extend this:
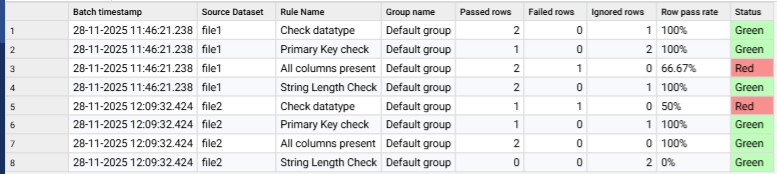
Validation rule results are captured in another multi-batch snapshot. Below, we see several rule failures where the loaded data does not match up to the file's associated metadata:
Resources
The Data Studio Workflow and Dataset objects shown here can be imported into your Data Studio instance using this .dmxd file (v3.1.10 and newer).
The data and metadata example files used are:
Please note that all data and metadata files used here are made up of only dummy data