Pushdown Processing on a pivot

Hi,
In testing Pushdown Processing today, I hit a couple of errors.
The first is simple to workaround by removing it (but would be awesome if the generation understood to omit) - the dataset query had a semi-colon at the end, which pushdown processing then put it's "as R0" after:
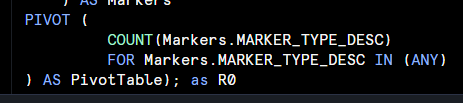
The second I'm still at a bit of a loss. I have another dataset that has similar columns:
"* Private Client"
"Private Client"
The issue is the generator seems to be effectively ignoring the "* " (maybe because of *'s significance in SQL as select all?) and therefore treating the column name as a duplicate, generating this SQL:

"'Private Client' 1" not being a column then causes the pushdown processing to error. The dataset column names are generated from a pivot, so I need to keep the naming convention ideally, to avoid hardcoding a fix and losing the convenience of the pivot.
TLDR: can the pushdown processing SQL generation be tweaked to handle semi-colons at the end of the query, and handle datasets where column names are identical, but for some text that's being ignored (in this case is "* ")
Thanks
Mike
Comments
-
Thanks Mike for the feedback. If you please can share a dmx file containing the Workflow and Dataset(s) [no data] that will help to investigate
0 -
Hi Josh,
Neither issue passes a source step, so the DMX wouldn't show much at all. I tinkered more and discovered it's not so much a pushdown issue directly, but a dataset one.
For the first "issue" (definitely a lesser concern as removing a character from a dataset is no real fuss!), replicated by creating a dataset connecting to Snowflake external system with a query as follows:
select * from someTable;
It will work fine - unless you try to pushdown process.Second issue I think is more legitimate - When you create a dataset using a pivot from Snowflake, it changes the name of the column on the dataset (for the below example, it will rename what natively ran in Snowflake produces a column 'Private Client' as 'Private Client' 1). Again, works in general usage, but errors on pushdown as the SQL generated contains a reference to the numbered name.
To replicate, you can create a dummy table in Snowflake as below, and pictures below that show the difference in the Snowflake output vs the Dataset output of column names:create or replace temporary table MadeUpMarkers
(
id number
, MarkerType varchar(30)
)
;
insert into MadeUpMarkers
values
(1, '* Private Client')
,(2, 'Private Client')
;-- this is the query that would live within Aperture to call and pivot the table
select *
from
(
select *
from MadeUpMarkers
)
pivot (
max(id)
for MarkerType IN (ANY)
) as PivotTable
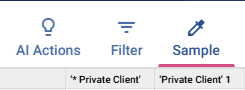
Quite niche…. but thought worth raising in case it can help make the dataset creation even more robust to horrid data values!
Thanks
Mike0
