Selecting Best Record with Harmonize Duplicates

There are times when you just want a quick way to deduplicate your data without necessarily knowing how many duplicates are found.
For example, you have a list of course completion status for a course OL100. There are multiple statuses recorded on different dates for each user. However, you are only interested in the latest course completion status for each user.

The easiest way to do this will be to connect your dataset to a Harmonize Duplicates step. The results will provide you with a list of unique User IDs and the latest course completion status.
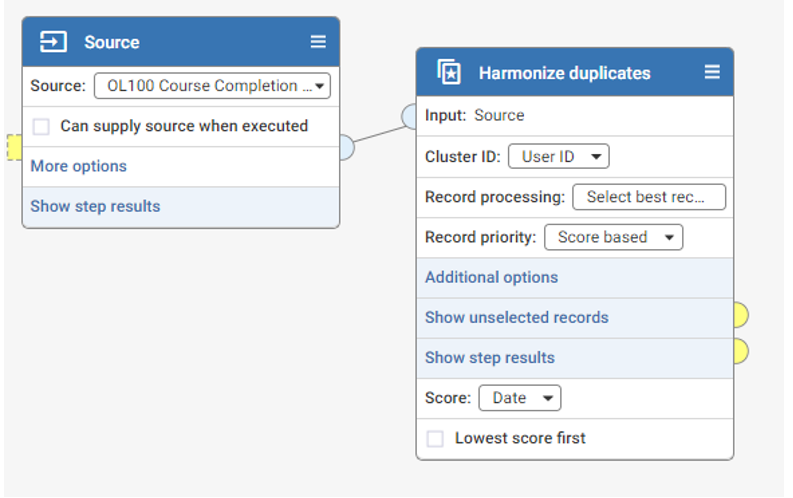

About the Harmonize Duplicates step:
- Harmonization is the process of deduplication - taking multiple records that are deemed to be for the same underlying real-world subject and producing a single resulting record.
- Cluster ID is the column containing the unique identifier for each group of records that are considered to be duplicates. Since we are trying to find the latest course completion status for each user, the User ID is the unique identifier.
- There are multiple Record processing options you can choose from to process the duplicate records. In this case, we use the default option, Select best record which identifies a single record in the group as the ‘surviving record’. All other records are ignored.
- Record priority determines the criteria that will be applied when selecting the best record. We use the Score based method so that we can determine which record is selected based on the latest course completion Date. Note: If you wanted to select the record with the earlier course completion Date, you can check on the Lowest score first checkbox.
Harmonize Duplicates can be used for simple scenarios such as this, but is actually typically used after a Find Duplicates step to select the best record. The Find Duplicates step provides the Cluster ID that can be used with Harmonize Duplicates.
Learn more about the Harmonize Duplicates step here.